리뷰 작성 : 김한결(https://www.linkedin.com/in/hangyeol-kim-227154228/)
본 논문을 읽기전에 알면 좋은 논문들
1. Behavior From the Void: Unsupervised Active Pre-Training - Hao Liu, Pieter Abbeel
0. Preliminary
Skill discovery란 explicit한 rewards 없이 다양한 스킬을 익힐 수 있는 학습 형태를 의미한다.
그런 의미에서 unsupervised RL과 의미적으로 유사한 점이 있다.
그러나 일반적인 unsuperivsed RL들은 의미없이 다양한 곳을 탐험하는 학습하는 것에 초점이 맞춰져있다.
본 논문은 "Semantic diversity"라는 것을 도입해서 의미론적인 다양성을 지난 상태를 방문하도록 유도한다는 점에서 skill discovery라는 말에 어울리는 방법을 제시한다.
LGSD를 읽기전 해당 논문에서 레퍼런스로 삼고 있는 APT 논문을 잠시 살펴보자.

APT는 Feature base로 계산된 entropy를 기반으로 a particle-based entropy estimation를 사용해서 다양한 상태에 도달할 수 있도록 장려하는 방법이다.

여기서 첫번째로 h를 계산하는 feature function $f_{\theta}$가 중요해보이며 두번째로 둘 간의 distance를 정의하는 중요해보인다.
1. Problem formulation
해당 논문의 첫 문장이 해당 논문이 나온 배경을 잘 설명해주고 있다고 생각한다.
One of the key capabilities of intelligent agents is to autonomously learn useful skills applicable to downstream tasks without task-specific objectives.
이걸 위해 본 해당 논문은 LGSD를 통해 3가지 원하는 바가 있다.
(i) 첫째로 semantic meaning을 가지고 있는 skill을 agent가 가지길 원한다. LLMs의 기술을 통해 각 에이전트의 상태를 기술하고 이를 바탕으로 상태들간의 semantic difference를 계산하고 language distance에 사용하며 이를 최대화하는 학습 방식을 사용한다.
(ii) 둘째로 의미론적으로 다른 subspace를 제한하길 원한다. 예를 들어 유아가 장난감을 발이나 입으로 물면 안되고 손으로만 잡도록 만들듯이. semantic meaning을 통해 이를 제한하고 싶다.
(iii) semantic meaning을 통해 배운 것들을 쉽게 재사용할 수 있도록 하고 싶다. 마치 zero-shot learning처럼, 그냥 구두로 설명하면 원하는 상태가 될 수 있도록.
그래서 LGSD의 contribution으로
1) semantically diverse skill을 익힐 수 있는 framework 제안
2) semantically diverse skill을 익힐때 공간 제한 방법을 제안
3) language-distance라는 걸 이론적으로 증명
4) natural language로 goal state에 도달하도록 만드는 agent
2. Language Guided Skill Discovery

MI는 KLD를 사용하기 때문에 종종 두 분포를 분리하기 어려운 특성이 있음. (distance에 대한 metric이 아니기 때문에)

그래서 많이 사용하는게 wasserstein distance. LGSD도 WDM을 사용한다.
LGSD의 학습 방법은 생각보다 간단하다.
우선 밑의 그림을 보자.

그림을 해석하자면, 프롬프트로 'how far the robot is from the origin'과 state를 통해 나온 'robot is far from the origin'과 'robot is near the origin'을 pretrained된 sentence-transfer을 이용해 fixed-vector로 바꾸고 거리를 계산함. 이걸 $d_{lang}$이라고 부르자. 그리고 우리는 $d_{lang}$이 먼 상태들을 많이 방문하고 싶다. -> 이게 의미적으로 멀다는걸 뜻하니까.
그럼 $d_{lang}$을 멀어지게 하려면 어떻게 해야될까?
이걸 하기 위해서 1-Lipschitz continuous를 만족하는 function $\phi$를 정의한다.
1-Lipschitz continuous를 만족한다면 latent space에서 $\phi(s)$와 $\phi(s')$를 멀어지게 만들면 자연스럽게 $d_{lang}$가 멀어지게 될테니까.
그럼 어떻게 $\phi(s)$와 $\phi(s')$를 멀어지게 만들 수 있을까?
latent space에서 isotropic Gaussian prior에서 랜덤하게 뽑아낸 벡터랑 내적한게 최대가 되게하면 된다.
자세한 증명은 appendix에 나와있다.(사실 직관적으론 와닿지가 않는다. 랜덤한 z와의 내적이 커진다고 $\phi(s) - \phi(s')$ 의 거리가 멀어진다고 생각하기 어렵긴하다.)
이를 수식으로 나타내면 아래와 같다. s.t. 부분은 추후에 라그랑주 승수법으로 최적화식에 포함시킨다.
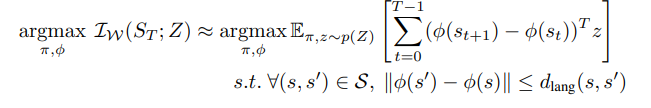
이로써 LGSD의 첫번째 contribution 1) semantically diverse skill을 익힐 수 있는 framework을 제안했다.
그 다음 내용은 두번째 contribution에 대한 Constraining the skill space via prompts이다.
LLM에게 prompt를 줄때 의미론적으로 구분될 수 있도록 한다. 이렇게 하면 의미없는 행동을 덜할 수 있게 탐험하는 space를 좁힐 수 있다. (사실 framework의 contribution에 일부인 것 같긴하다)
논문에는 다음과 같은 예시가 있다.

물체가 움직이지 않을 경우 물체와 로봇 팔 사이의 거리 $d_1$을 설명하도록 하고 로봇 팔이 큐브에 도달했을때 물체가 이동한 거리 $d_2$를 설명하도록한다. 그럼 의미적으로 $d_1$을 설명할때와 $d_2$을 설명할때 $d_{lang}$의 차이가 크기 때문에 $d_1$을 기술하다가 $d_2$를 기술하는 상태를 자주 방문하고 싶어할 것이다.
(그런데 이렇게 하는게 사실 supervised에 가깝다고 생각. implicit하게 줬을 뿐이지 프롬프트로 d1과 d2를 얻는 상태를 '명시적'으로 구분해줬기 때문에, 팔을 가져다가 놓으라고 알려주는 것과 다를 바가 없을것 같다. 본 논문이 추구하는 autonomously learn useful skills applicable to downstream tasks without task-specific objectives와는 거리가 있어 보인다.)
세번째는 language-distance의 이론적으로 증명인데, 증명은 힘드니 간단히 $d_{lang}$을 어떻게 계산하는지 알아보자.
첫번째 contribution을 설명할때 대략적으로 $l_{desc}(s)$에 대해 언급을 했었다. LLM에 프롬프트랑 벡터형태의 state를 text로 바꿔서 넣어주면 그게 $l_{desc}(s)$이 되고 이를 다시 pre-trained된 language embedding model에 넣어 벡터형터로 뽑아내면 그게 현 상태의 semantic vector를 계산한 것이다.
vector의 거리는 또다시 내적으로 계산되는데 식(2)의 두번째항은 항상 $cos(\theta)$범위 안에 있으니 -1보다 크고 1보다 작다. 즉 완전이 같으면 거리가 0이 되고 최대 거리는 2가 된다.

마지막 네번째 contribution인 natural language로 goal state에 도달하도록 만드는 agent를 보자.
사실 LGSD에서 goal state로 zero-shot learning을 하는건 굉장히 단순해보인다. 원래 사용했던 prompt와 목표로 하는 goal state로 넣어주면 목표로하는 임베딩 z를 얻을 수 있을 테니까 이걸 그냥 그대로 $\pi(s,z)$에 넣어주기만 하면된다.
그런데 사실 goal state를 얻기가 어렵다. 논문에서 나온 예로 큐브의 최종 위치와 자세는 알기 쉽지만 이걸 달성했을때 로봇팔의 위치와 자세는 미리 알기 어렵기 때문이다. 그래서 $\psi: f_{embd}(l_{desc}) -> z$를 훈련시켜서 설명으로 $z$를 추론시키도록 만든다.
3. Result
이제 결과를 살펴보자.
첫번째 실험은 prompt로 semantic space를 제한할 수 있는지 확인하는 시험이다. 에이전트는 어디로든 갈 수 있지만 prompt로 NSWE 중 한쪽 방향으로만 가도록 지시를 한다. 아래 보이는 바와 같이 신기하게도 agent가 움직이는 공간이 '의미적'으로 제한된 것을 볼 수 있다.

두번째 실험은 다른 unsupervised에 비해 얼마나 다양한 스킬을 얻을 수 있는지 보는 실험이다. Franka로부터 최대한 큐브를 멀리 떨어뜨려놓고 큐브가 얼마나 다양하게 잘 움직이는지 본다.

마지막으로 $\psi(z|f_{embed}(l_{desc}))$의 효과를 보이는 실험이다. 조금 더 자세히 말하자면 $\psi$를 통해 원하는 목표 상태에 도달하기 위한 스킬을 $z$ 차원에서 추론하는 것이다. 예를 들어 '물체가 [0.3, 0.2]'에 있다 와 같은 단순한 설명에는 로봇의 위치나 자세가 포함되어 있지 않음에도 $\psi$를 통해 물체를 원하는 위치로 이동시키는 시나리오를 얻을 수 있다. 이로써 zero-shot 방식으로 큐브를 원하는 위치에 가져다 놓을 수 있는 policy를 얻을 수 있다.




