참여자 : 백종찬(POSTECH), 김한결(POSTECH), 권우경(ETRI & Polaris 3D)
작성자 : 김한결 / 석사과정(gksruf621@postech.ac.kr)
지난 포스터에서는 RRC 2022의 문제 설계에 대해 살펴보았다.
이번 포스터에서는 시뮬레이션 단계에서 테스트 해본 알고리듬들을 소개할 예정이다.
알고리듬을 소개하기 이전에 데이터에 대해 잠시 언급해야할 부분이 있다. rrc_2022_datasets 패키지를 다운 받으면 TriFingerDatasetEnv에 접근할 수 있고, D4RL과 동일하게 get_dataset() 매소드를 통해 데이터 접근이 가능하다. 단, TriFingerDatasetEnv를 evaluation하는 과정에서 얻는 데이터들은 오직 평가를 위해서만 사용되어야하며, 학습 과정에는 포함될 수 없다.
아래 task 이름에서 알 수 있듯이 해당 데이터는 expert 데이터만을 포함하고 있다.
Pushing Task : “trifinger-cube-push-sim-expert-v0”
Lifting Task : “trifinger-cube-lift-sim-expert-v0”
알고리듬 목록은 다음과 같다.
1. Behavioral clonning
2. Decision Transformer
3. Conservative Q-Learning
1. Behavioral clonning (BC)
BC를 한마디로 간단하게 표현하자면, state와 action pair를 supervised learning (SL) 하는 것이다. 이는 state에 대해 매칭되는 action의 확률을 높이는 것이며, 이를 수학적으로 나태내면 다음과 같다.

안타깝게도 강화학습은 closed loop 문제이지만, SL로 학습한 정책은 open loop에 가깝다. 이와 관련된 큰 문제 중에 하나가 model error가 발생했을때 성능의 degradation이 time horizon의 제곱에 비례하게 된다. 이는 dataset에 non-expert data가 포함될 경우 더욱 치명적이다 (물론 MARWIL, BAIL 같이 이를 완화하는 알고리듬들이 여럿 제안되었습니다).

더욱이 BC의 성능은 항상 dataset에 bound될 수 밖에 없는데, 달리 말해 dataset을 생성한 policy보다 더 좋은 성능을 기대하기는 어렵다는 뜻이다. 그럼에도 불구하고 BC는 expert의 행동을 imitate하는데에는 가장 간단하며 꽤나 좋은 성능을 보이기 때문에 Benchmark로 사용하기에는 충분히 좋은 알고리듬이다.
2. Decision Transformer [2]
기존의 강화학습 문제를 sequence modeling problem으로 생각하여 풀어낸 논문이다. 기존의 강화학습 이론을 전혀 사용하지 않기 때문에 이론적인 분석이 없지만, 구조적으로 보았을때 stacked state로 수행한 BC로 이해하면 된다. Transformer architecture관점에서 바라보면 GPT는 문장의 생성에 적합한 구조이고 이는 sequence를 결정하는 능력을 학습한다고 이해할 수 있다.

SOTA 알고리듬이기 때문에 DT를 Benchmark로 선정하게 되었다. 하지만 DT가 가지고 있는 한계점은 inference 시간이 다른 모델에 비해 너무 크다는 것이다. 때문에 real robot stage에서는 DT를 사용하지 않았다 (robot 명령을 주는데 시간 제한이 있음).
3. Conservative Q-Learning [3]
<CQL의 이론적인 부분에 대해서는 논문을 직접 보거나 다른 블로그를 참고하시는 것을 추천합니다>
CQL를 한마디로 설명하자면, "dataset에 있는 action을 고평가 하고 dataset에 없는 action은 저평가 하겠다"이다.
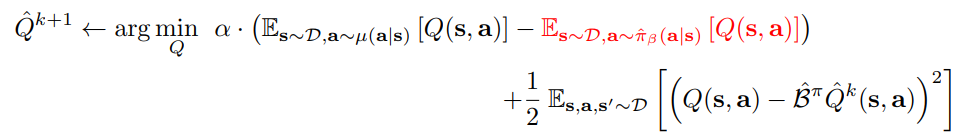
위 수식은 CQL 논문의 2번 수식이다. $\mu$는 uniform distribution이라고 생각하면 되고 $\hat{\pi}_{\beta}$는 emprical distribution으로 데이터셋의 action 분포라고 생각하면 된다. 위 수식의 첫번째 텀은 uniform 분포에서 나온 action들은 Q가 낮아지도록 유도하는 것이고 두번째 텀은 emprical distribution에 대한 Q가 높아지도록 유도하는 것이다. 세번째 텀은 일반적으로 Q를 학습할때 사용하는 bellman equation을 TD로 푸는 것이다. 즉 dataset에 있는 action을 고평가 하고 dataset에 없는 action은 저평가 하겠다는 것으로 볼 수 있다.
Appendix를 읽으면서 아름다운 논문이라고 생각했지만 구현적인 관점에서는 생각보다 실망스러운 알고리듬이다. 다른건 차치하더라도 하이퍼 파라미터가 너무 많아서 sweet spot을 찾기가 매우 힘들다.
[알고리듬 성능평가]
| Algorithm | dataset | BC | DT | CQL |
| Push-expert | 674 | 675 | 685 | 303 |
| Lift-expert | 1332 | 1131 | 1183 | 280 |
CQL 같은 경우 하이퍼 파라미터를 여럿 조정해보았지만 성능 향상을 기대하기가 어려웠으며 학습 과정에서도 성능의 고저 차이가 심했다. 물론 D4RL 환경에서의 하이퍼 파라미터 근방에서 조정했기 때문에 이런 결과가 나왔을 수 있지만, 본 대회와 같이 실제 환경에서 운용해야 할때는 하이퍼 파라미터에 민감한 알고리듬은 좋은 알고리듬이 아니다. DT와 같은 경우 일반적으로 좋은 성능을 보였지만 inference 시간이 길다는 것이 치명적인 단점이다. 생각외로 BC가 높은 성능을 보였는데, dataset이 오직 expert data만을 포함하고 있기 때문이며 real robot단계에서는 mixed dataset에 대해서도 평가를 해야하기 때문에 다른 방법을 모색해 봐야했다.
다음 포스터에서는 real robot task에서 사용한 알고리듬을 소개할 예정이다.
[1] S. Ross and J. A. Bagnell. Efficient reductions for imitation learning. In Proceedings of the 13th International Conference on Artificial Intelligence and Statistics (AISTATS), 2010.
[2] Chen, Lili, et al. "Decision transformer: Reinforcement learning via sequence modeling." Advances in neural information processing systems 34 (2021): 15084-15097.
[3] Kumar, Aviral, et al. "Conservative q-learning for offline reinforcement learning." Advances in Neural Information Processing Systems 33 (2020): 1179-1191.
'Others' 카테고리의 다른 글
| CO-GYM: 빠르고 효율적인 강화학습 프레임워크 (3) | 2024.07.18 |
|---|---|
| Nips challenge - Real Robot Challenge 2022 도전기 (2) (4) | 2022.10.12 |
| Nips challenge - Real Robot Challenge 2022 도전기 (1) (6) | 2022.10.05 |
| Mujoco 환경 세팅 - 참고용 (2) | 2022.06.29 |
| MJCF 파일 분석(5) - 나만의 Manipulator task를 mujoco에서 만들자 (2) | 2022.04.03 |


