참여자 : 백종찬(POSTECH), 김한결(POSTECH), 권우경(ETRI & Polaris 3D)
작성자 : 김한결 / 석사과정(gksruf621@postech.ac.kr)
Real Robot Challenge 2022 (RRC 2022)
Learn Dexterous Manipulation on a Real Robot
지난 포스터에서는 RRC 2022개요에 대해 설명하였다. 이번 포스터에서는 강화학습 관점의 문제 설계를 살펴볼 내용이다.
Observation space
- robot_observation
- position
- velocity
- torque
- fingertip_force
- fingertip_position
- fingertip_velocity
- robot_id
- object_observation
- position
- orientation
- keypoints
- delay
- confidence
- action – This contains the action from the previous step
- desired_goal
- $position^1$
- $keypoints^2$
- achieved_goal
- $position^1$
- $keypoints^2$
1은 오직 Pushing Task에만 존재하고 2는 lifting task에만 존재한다. 총 차원은 pushing에서 97차원, lifting에서 139 차원이다.
특이한 점은 observation에 robot id 포함되어 있다는 것이다. 이전 포스터에서 살짝 언급했던 바와 같이 제출한 policy를 클러스터서버에 올리면 현재 작업을 수행하고 있지 않은 로봇에 할당되어 에피소드가 실행되기 때문에, 매번 evaluation하는 로봇이 달라진다. evaluation하는 로봇이 달라진다는 것은 transition probability가 조금씩 달라진다는 것이기 때문에 이를 구분할 수 있도록 robot id가 주어진 것이다. (하지만 실제 데이터를 보면 robot id는 observation에 없었다...하하)
또다른 특이점은 object_observation안에 있는 confidence라는 state이다. 로봇이 밀거나 들어올리는 cube의 position, orientation을 계측할 수 있어야하는 데, rrc 2022에서는 카메라를 이용하여 이를 추정한다. 하지만 이는 언제나까지 추정치이기 때문에 이에대한 confidence가 추가로 주어진것으로 보인다.
Action space
The actions are the torques send to the actuators in the 3 joints of the 3 fingers. The torque range is [-0.397, 0.397].
총 차원은 9차원이며, action space는 각 관절의 토크 값이다. (딱히 특별한 점이 없다)
Reward formulation
The reward is computed by applying a logistic kernel to an input $x$:
$k(x) = \frac{b+2}{exp(a||x||)+b+exp(-a||x||)}$
여기서 $x$는 cube의 position 혹은 keypoint이다. 위 수식을 그래프로 그리면 다음과 같은 종모양을 갖는다.
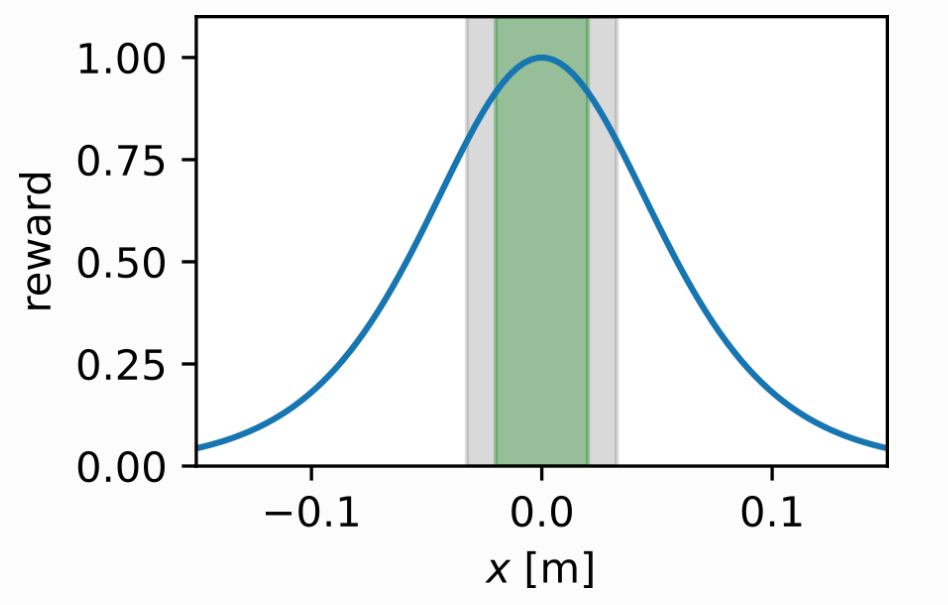
위 그림에서 초록색 부분은 0.02[m] 구간이며 해당 구간내에 cube의 position 혹은 keypoint가 들어왔을때 success로 취급한다.
본래 강화학습 문제 설계가 강화학습의 핵심이라고 생각하지만 현 task는 logged data로 학습하는 offline reinforcement이기 때문에 그렇게 공들여서 바라볼 필요는 없는것 같다.
다음 포스트에서는 simulation stage에서 시도했던 알고리듬을 소개할 예정이다.
'Others' 카테고리의 다른 글
| CO-GYM: 빠르고 효율적인 강화학습 프레임워크 (0) | 2024.07.18 |
|---|---|
| Nips challenge - Real Robot Challenge 2022 도전기 (3) (0) | 2022.11.07 |
| Nips challenge - Real Robot Challenge 2022 도전기 (1) (1) | 2022.10.05 |
| Mujoco 환경 세팅 - 참고용 (1) | 2022.06.29 |
| MJCF 파일 분석(5) - 나만의 Manipulator task를 mujoco에서 만들자 (0) | 2022.04.03 |


